
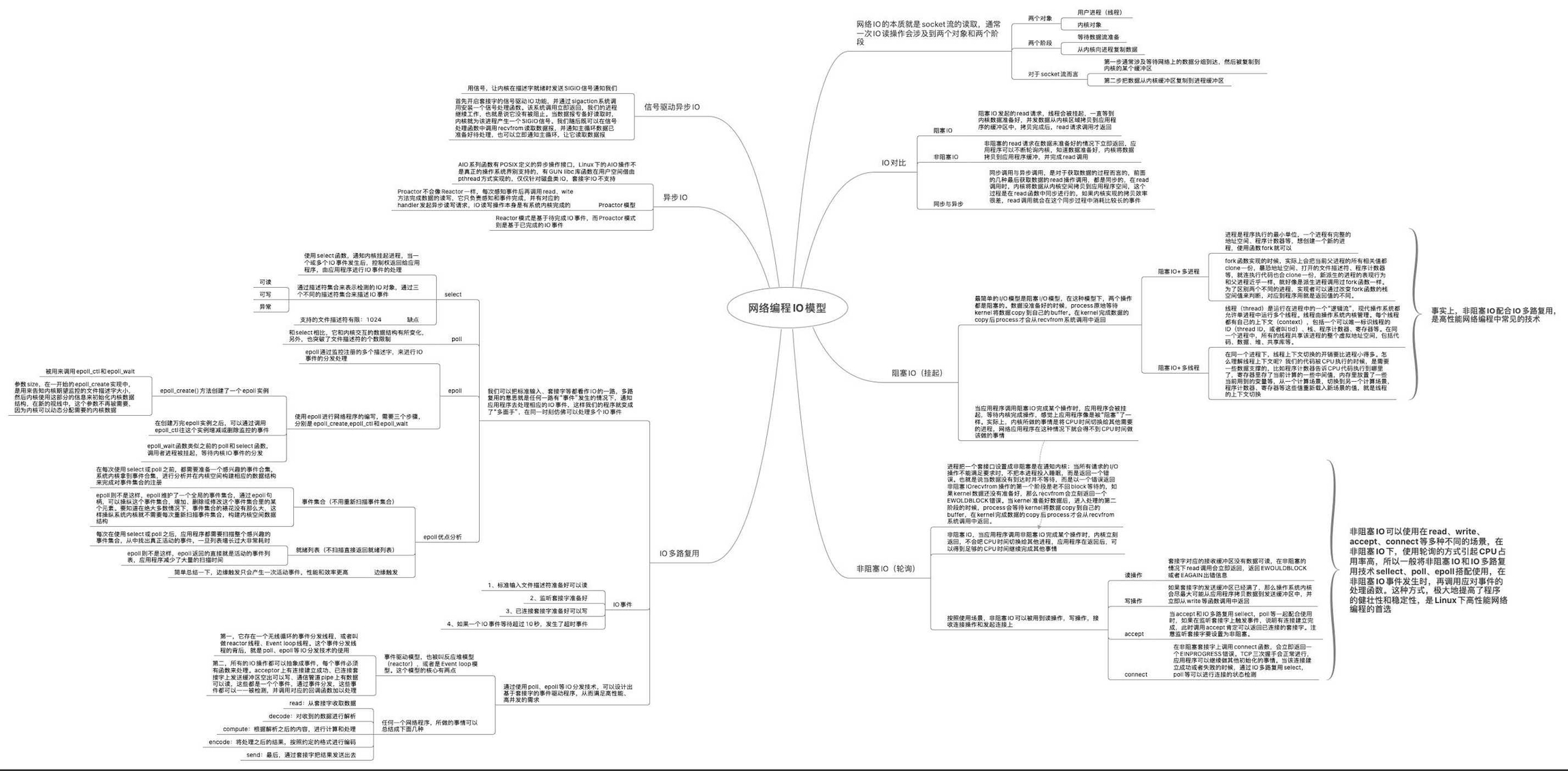
压测到网络IO
wrk压测
wrk命令参数
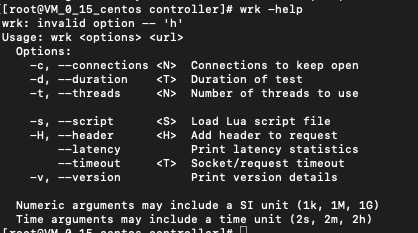
服务器为腾讯云虚拟机,1核2G
ThinkPHP5.0结果
nginx+php-fpm
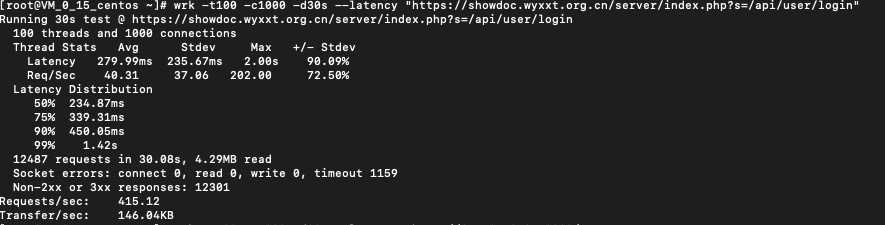
gin结果
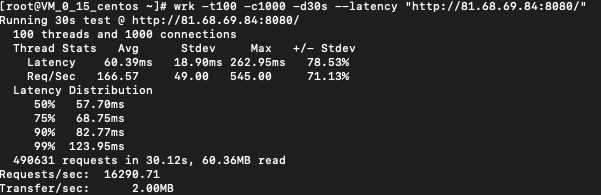
页面都是输出Hello World!,性能差距40倍。为什么差距会这么大?网络IO模型是根本原因。PHP是阻塞IO+多进程模型,gin主从reactor+worker threads模型(JAVA框架Netty也是)。
三大网络模型
1、阻塞IO+多进程
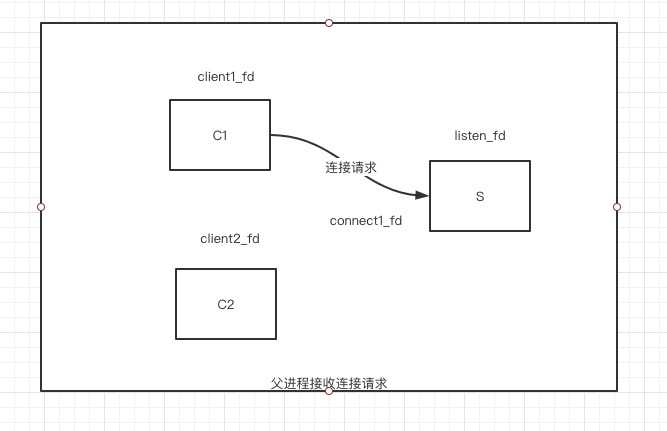
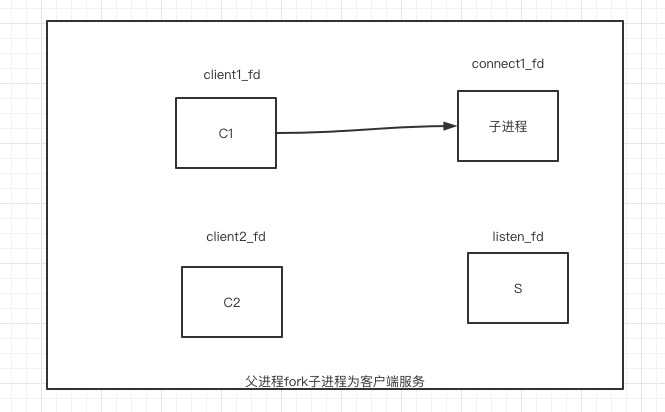
一切接文件,文件描述符也可以表示网络socket 服务启动,监听listen_fd文件描述符(表示网络socket),此时客户端发起一个连接请求,连接成功后产生连接套接字(ip:port-ip:port唯一标识一个连接),此时父进程fork出一个子进程,子进程拿到连接套接,并以此与客户端通信。此模型中,父进程关心的是监听套接字,子进程关心的是连接套接字。
弊端
进程切换上下文,代价高
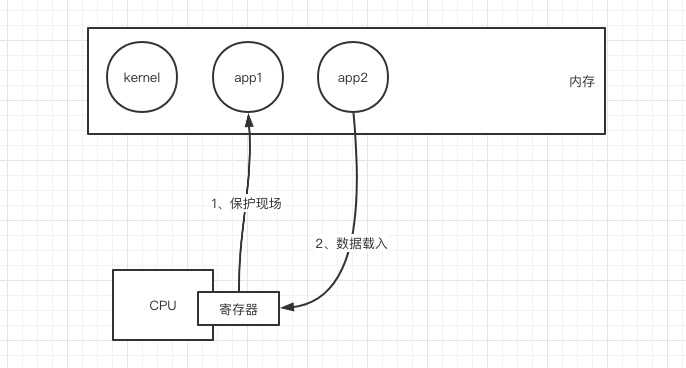
2、阻塞IO+多线程
进程线程的切换都是需要内核操作,这就涉及到用户态和内核态的切换
类似进程,切换开销比进程小
因为线程由操作系统内核管理,在同一个进程中,所有的线程共享该进程的整个虚拟地址空间,包括代码、数据、堆、共享库等。 我们的代码被CPU执行需要一些数据支撑的,这就是所谓的上下文,包括但不限于程序计数器需要告诉CPU代码执行到哪里了,寄存器中存放了一些计算中间值,内存中存放了当前一些变量等。从一个计算场景切换到另一个计算场景,这些值都需要重新载入,这就是上下文切换。
3、 非阻塞IO+多路复用
使用select、poll和epoll可以设计出基于套接字,满足高性能,高并发的事件驱动程序。 事件驱动模型又叫**reactor模型,或者Even loop模型。**这个模型的核心有亮点:
存在一个无限循环的事件分发线程,叫reactor线程,或者Even loop线程。这个分发线程背后的技术就是poll与epoll这类的IO多路复用技术。
所有的IO操作都可抽象为事件,每个事件必须有回调函数来处理。acceptor上有连接建立,已连接套接字的发送缓冲区可以写,通信管道pipe上有数据可以读,这些事件通过事件分发,都能被检测并调用回调函数处理。
单reactor模型+worker threads
该模型是将acceptor上连接建立时间,和已连接套接字的IO事件的分发由一个reactor线程去执行。由工作线程去处理耗时操作,例如数据读取,文件解析,计算,数据发送。
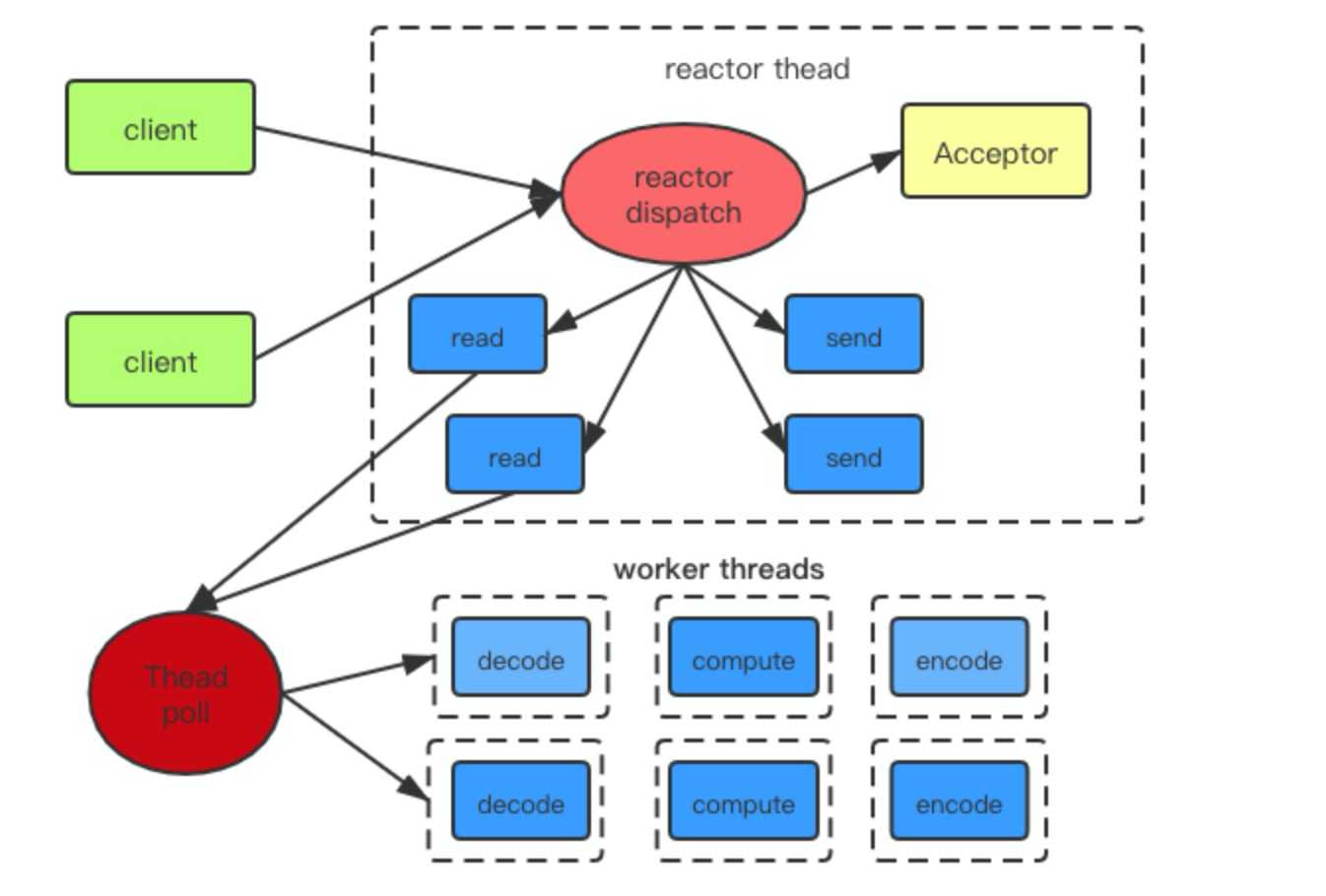
弊端
所有acceptor的连接建立事件和已连接套接字的IO事件交由一个reactor线程处理,在并发量较高的情况下,这个reactor线程会忙不过来,表现在客户端连接建立成功率偏低。
解决方案
将连接建立事件与已连接套接字的IO事件交由不同线程来处理,一个主reactor负责建立连接,多个从reactor负责IO事件
主从reactor模型+worker threads
那么主从模式的核心思想就在于,主reactor上只监听acceptor上成功建立的连接事件,并将其分发给从reactor线程,从reactor线程只需要负责已连接套接字上的IO事件。
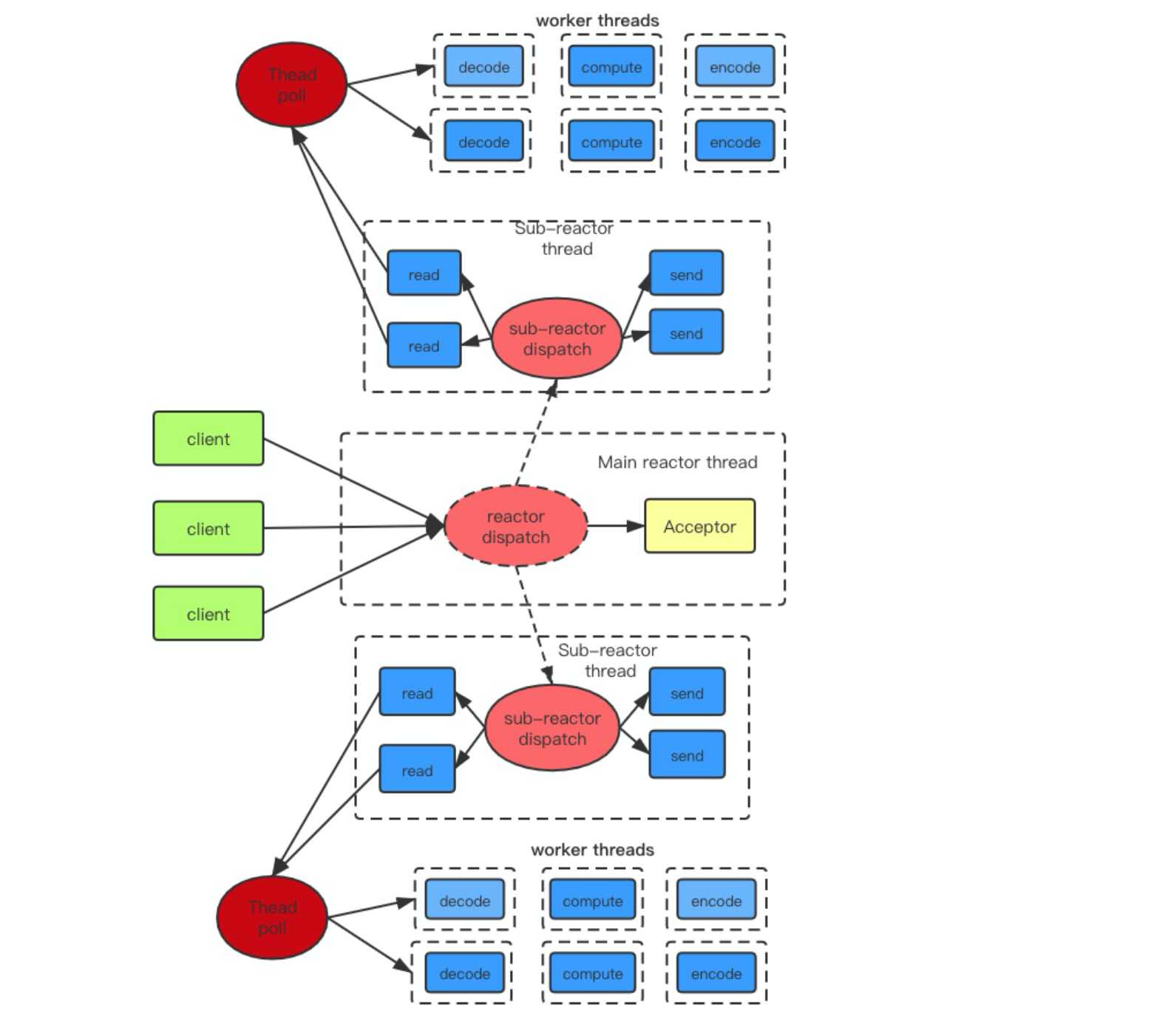
通过主reactor线程来分发成功建立的套接字,通过从reactor线程来分发已连接套接字上的IO事件,通过工作线程来处理耗时操作!
弊端
cpu切换工作线程,内核态和用户态的切换代价大。使用协程,子程序切换不是线程切换,而是由程序自身控制,在用户态完成。
五种网络IO
阻塞IO
当应用程序调用阻塞IO完成某个操作时,应用程序会被挂起,感觉上应用程序像是被“阻塞”了一样。实际上,内核所做的事情是将CPU时间切换给了其他有需要的进程,网络应用程序在这种情况下就会得不到CPU时间做该做的事情。
非阻塞IO
当应用程序调用非阻塞IO完成某个操作时,内核立即返回,不会把CPU时间让出给其他进程,应用程序在返回后可以得到足够的CPU时间做其他的事情。
IO多路复用
我们可以把标准输入、套接字都看作IO的一路,多路复用的意思,就是在任何一路IO有“事件”发生的情况下,通知应用程序去处理相应的IO事件,这样我们的程序就“好像”在同一时刻处理多个IO事件。
异步IO
当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
信号驱动IO
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行。当数据报准备好读取时,内核就为该进程产生一个SIGIO信号,我们随后可以在信号处理函数中读取数据报,也可以立即通知主循环,让他读取数据。
网络IO的本质
网络IO的本质就是socket流的读取,通常一次IO读操作会涉及到两个对象和两个阶段。
两个对象
用户进程(线程)
内核对象
两个阶段
等待数据流准备
从内核向进程copy数据
对于socket流而言:
第一步通常涉及等待网络上的数据分组到达,然后被copy到内核的某个缓冲区
第二步把数据从内核的缓冲区copy到进程缓冲区
如何区分阻塞IO和非阻塞IO
阻塞IO发起的read请求,线程会被挂起,一直等到内核数据准备好,并把数据从内核区域拷贝到应用程序的缓冲区中,拷贝完成后,read请求调用才返回。
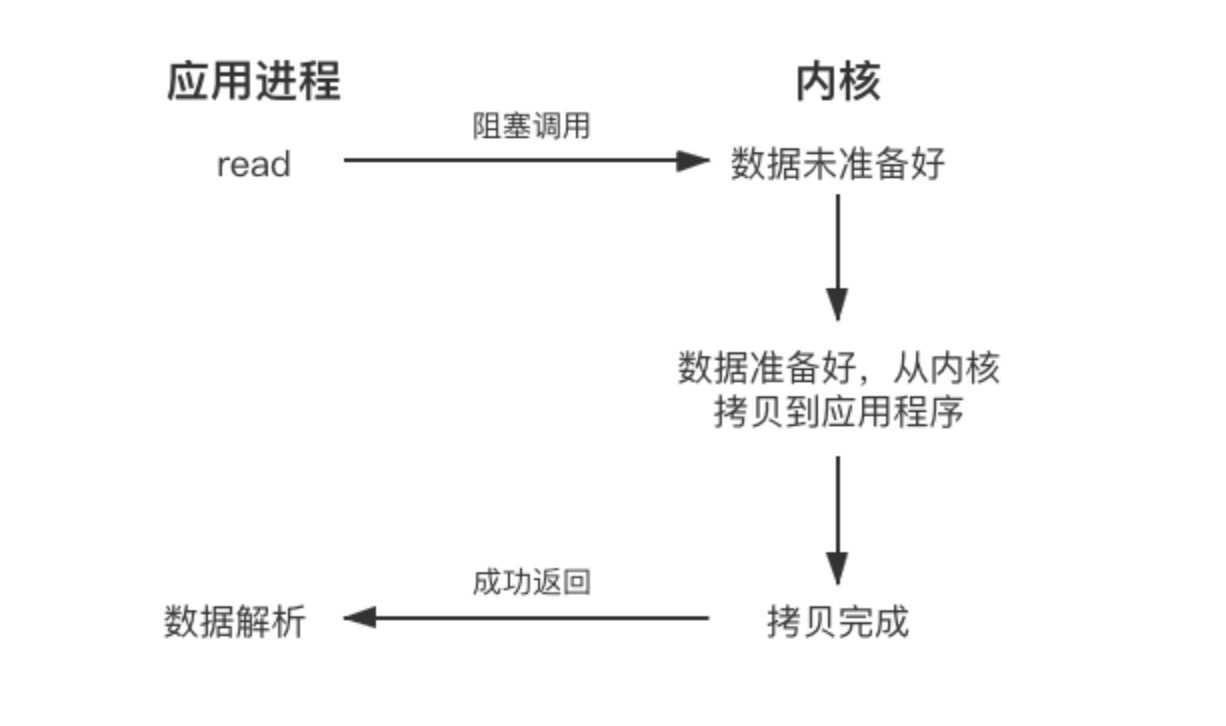
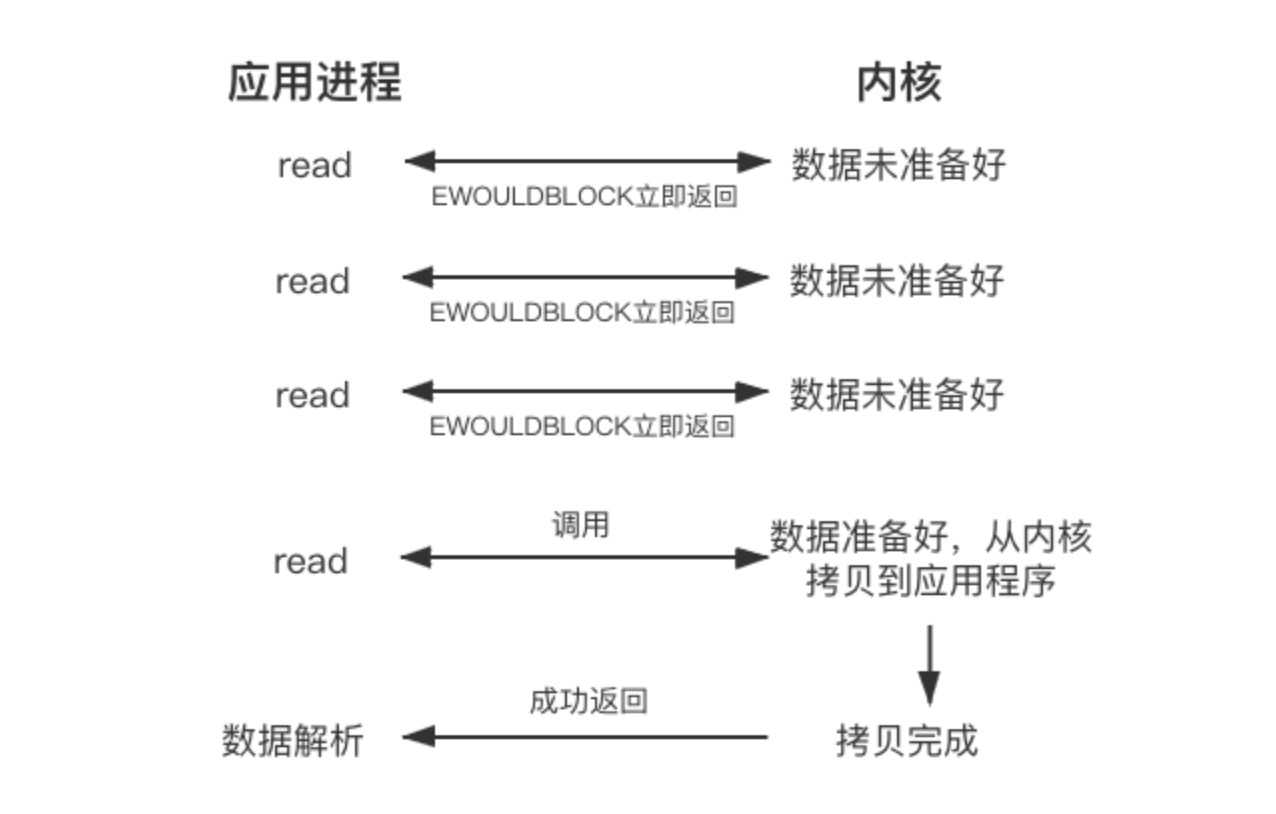
非阻塞IO的read请求在数据未准备的情况下立即返回,应用程序可以不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区并完成这次read调用。
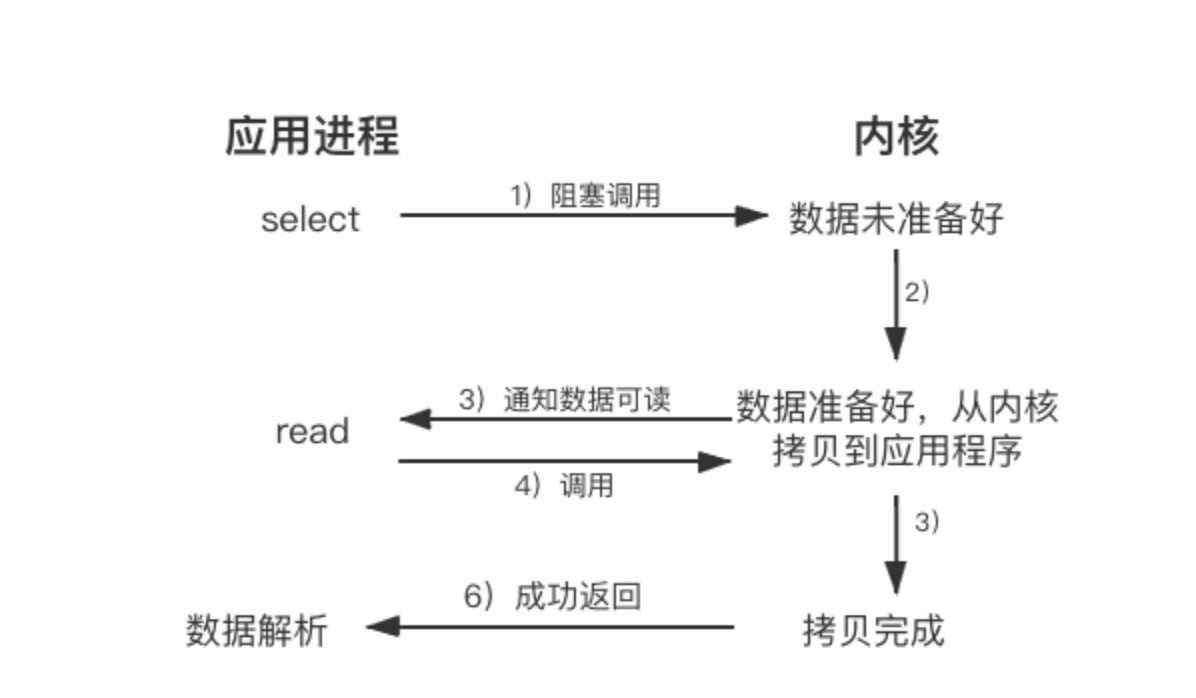
如何区分同步和异步
同步调用与异步调用是对于获取数据的过程而言的,前面的几种最后获取数据的read操作调用,都是同步的,即在read调用时,内核将数据从内核空间拷贝到应用程序空间,这个过程是在read函数中同步进行的。
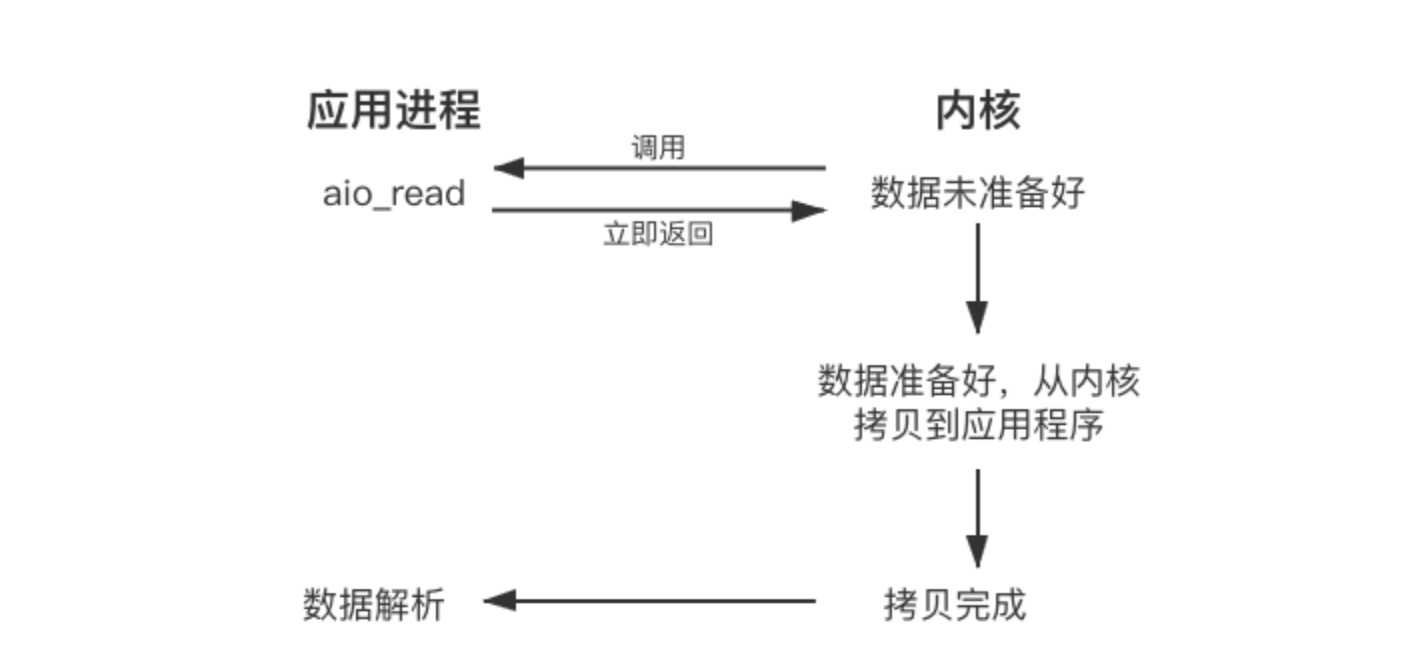
当我们发起异步读(aio_read)之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。
网络IO思维导图
最后更新于