
6.1缓存一致性问题
数据库能有很好的事务保证、持久化保证。但是,正因为数据库要能够满足这么多优秀的功能特性,使得数据库在设计上通常难以兼顾到性能,因此往往不能满足大型流量下的性能要求,像是 MySQL 数据库只能承担“千”这个级别的 QPS,否则很可能会不稳定,进而导致整个系统的故障。
大部分的流量实际上都是读请求,而且大部分数据也是没有那么多变化的,如热门商品信息、微博的内容等常见数据就是如此。此时,缓存就是我们应对此类场景的利器。
缓存的意义
利用空间换时间,用更高速的空间来换时间,从而整体上提升读的性能。
更快的存储介质。通常情况下,如果说数据库的速度慢,就得用更快的存储组件去替代它,目前最常见的就是 Redis(内存存储)。Redis 单实例的读 QPS 可以高达 10w/s,90% 的场景下只需要正确使用 Redis 就能应对。
使用本地内存。就像 CPU 也有高速缓存一样,缓存也可以分为一级缓存、二级缓存。即便 Redis 本身性能已经足够高了,但访问一次 Redis 毕竟也需要一次网络 IO,而使用本地内存无疑有更快的速度。不过单机的内存是十分有限的,所以这种一级缓存只能存储非常少量的数据,通常是最热点的那些 key 对应的数据。这就相当于额外消耗宝贵的服务内存去换取高速的读取性能。
引入缓存后的一致性挑战
用空间换时间,意味着数据同时存在于多个空间。最常见的场景就是数据同时存在于 Redis 与 MySQL 上。
只要使用了缓存,就必然会有不一致的情况出现,只是说这个不一致的时间窗口是否能做到足够的小。有些不合理的设计可能会导致数据持续不一致,这是我们需要改善设计去避免的。
缓存不一致性无法完全消灭
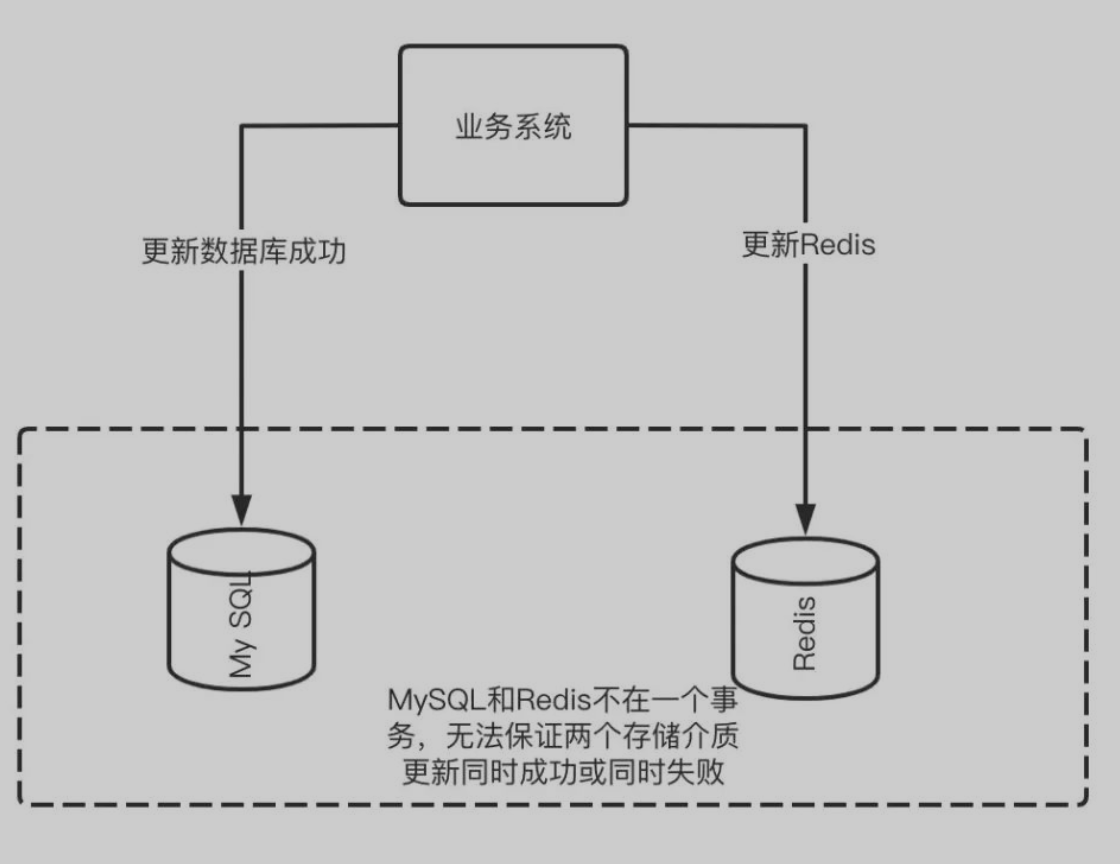
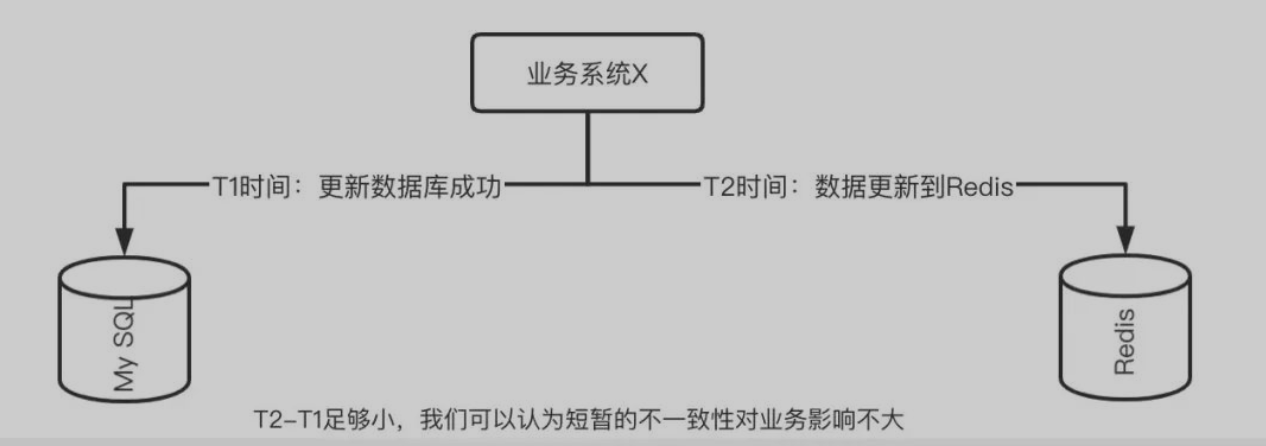
时间窗口是没办法完全消灭的,除非我们付出极大的代价,使用分布式事务等各种手段去维持强一致,但是这样会使得系统的整体性能大幅度下降,甚至比不用缓存还慢,这样就与我们使用缓存的目标背道而驰。不去追求强一致性,追求最终一致,不一致的时间窗口我们能做到尽可能短。
更新缓存的手段
优先查询缓存,查询不到才查询数据库。如果这时候数据库查到数据了,就将缓存的数据进行更新。这是我们常说的 cache aside 的策略,也是最常用的策略。
一致性的问题一般不来源于此,而是出现在处理写请求的时候。
写请求的逻辑,此时你可能会面临多个选择,究竟是直接更新缓存,还是失效缓存?而无论是更新缓存还是失效缓存,都可以选择在更新数据库之前,还是之后操作。
更新数据库后更新缓存、更新数据库前更新缓存、更新数据库后删除缓存、更新数据库前删除缓存
**从一致性的角度来看,采取更新数据库后删除缓存值,是更为适合的策略。**因为出现不一致的场景的条件更为苛刻,概率相比其他方案更低。
如何保证最终一致性
设置缓存过期时间
使用缓存的时候,我们必须要给缓存设置一个过期时间,例如 1 分钟,这样即使出现了更新 Redis 失败的极端场景,不一致的时间窗口最多也只是 1 分钟。
这是我们最终一致性的兜底方案,万一出现任何情况的不一致问题,最后都能通过缓存失效后重新查询数据库,然后回写到缓存,来做到缓存与数据库的最终一致。
如何减少缓存操作失败导致的不一致
消息中间件
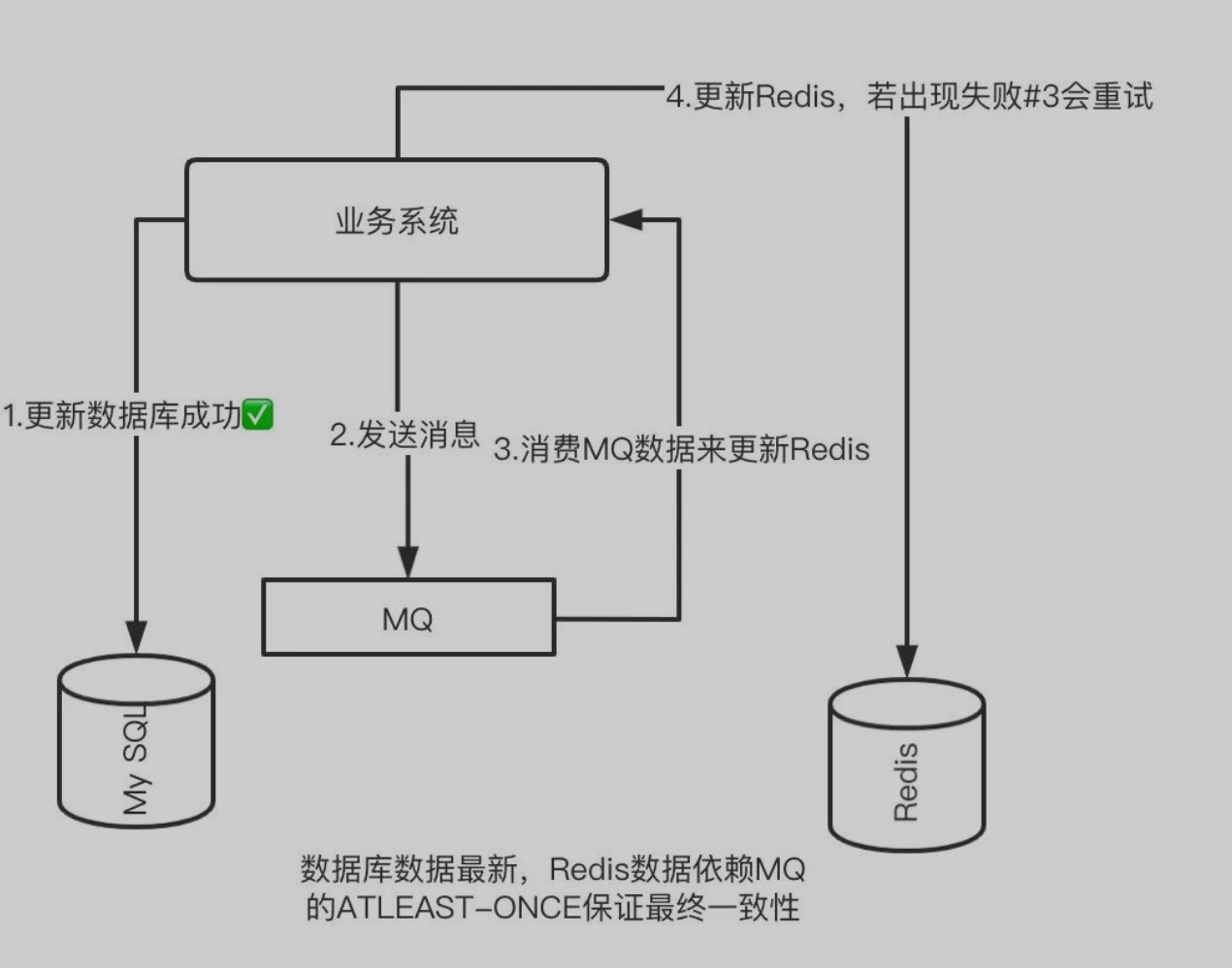
rocketmq 事务消息 或者 消息表 来确保消息一定发送成功
如何处理复杂的多缓存场景
有些时候,真实的缓存场景并不是数据库中的一个记录对应一个 Key 这么简单,有可能一个数据库记录的更新会牵扯到多个 Key 的更新。还有另外一个场景是,更新不同的数据库的记录时可能需要更新同一个 Key 值,这常见于一些 App 首页数据的缓存。
针对这个场景,解决方案和上文提到的保证最终一致性的操作一样,就是把更新缓存的操作以 MQ 消息的方式发送出去,由不同的系统或者专门的一个系统进行订阅,而做聚合的操作。
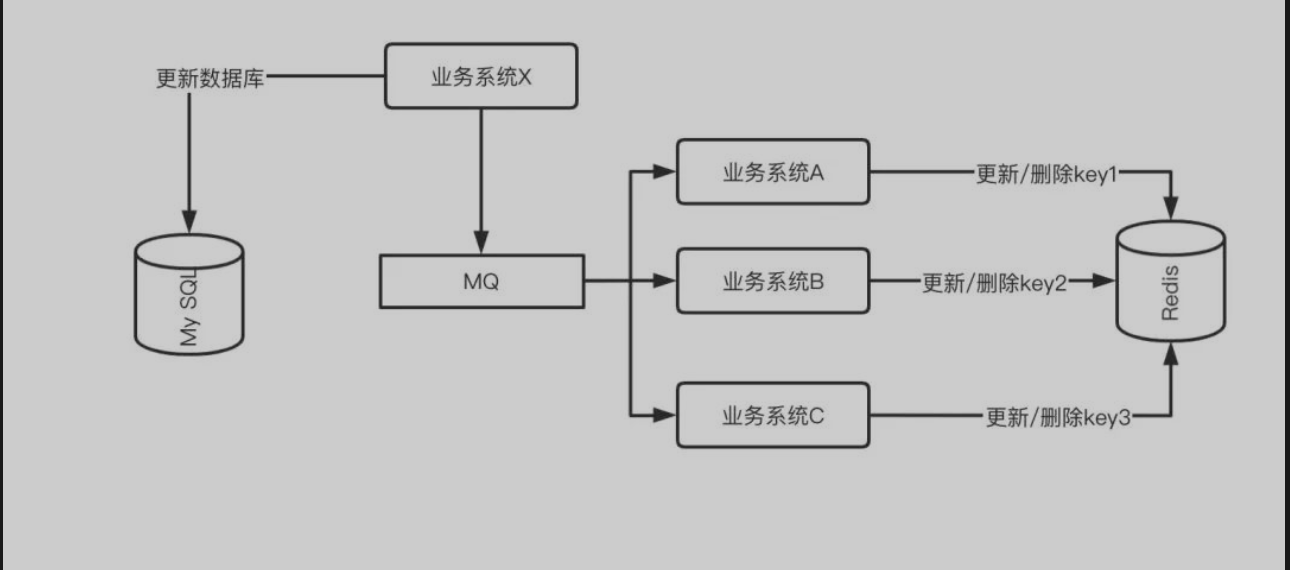
不同业务系统订阅 MQ 消息单独维护各自的缓存 Key
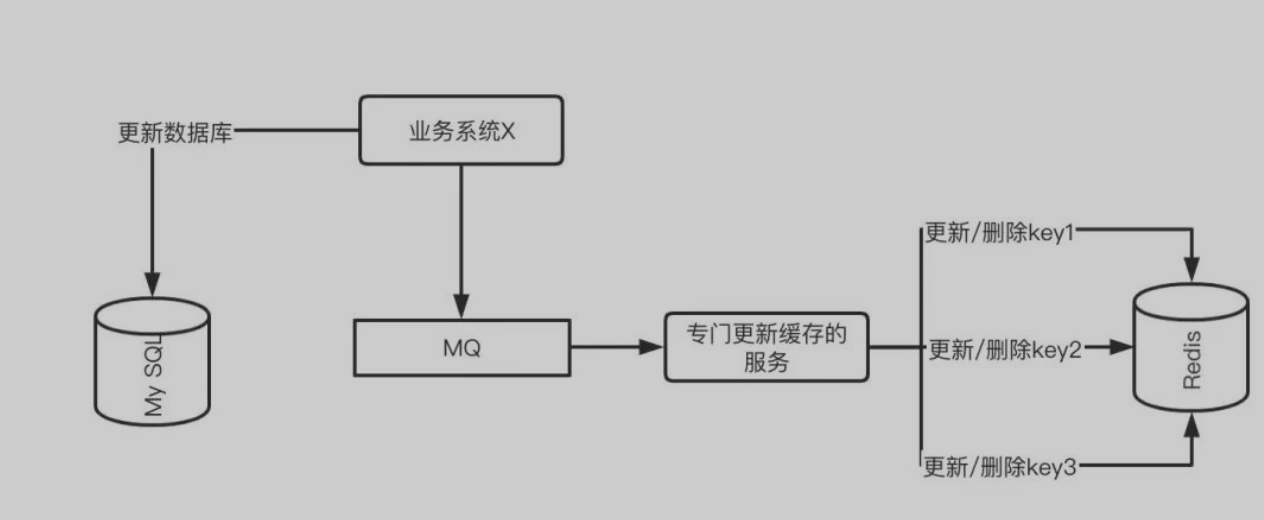
专门更新缓存的服务订阅 MQ 消息维护所有相关 Key 的缓存操作
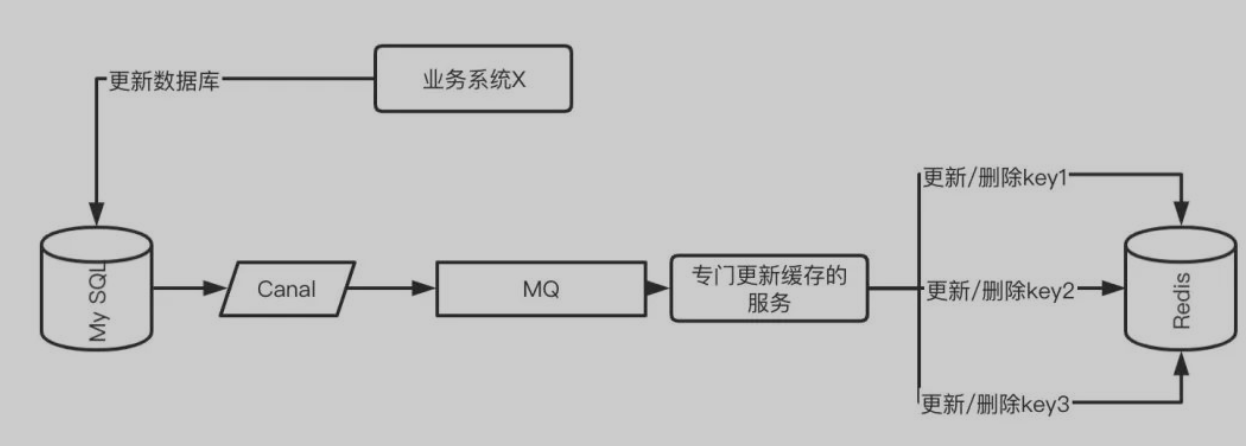
通过订阅 MySQL binlog 的方式处理缓存
上面讲到的 MQ 处理方式需要业务代码里面显式地发送 MQ 消息。还有一种优雅的方式便是订阅 MySQL 的 binlog,监听数据的真实变化情况以处理相关的缓存。
最后更新于