
1.1执行过程
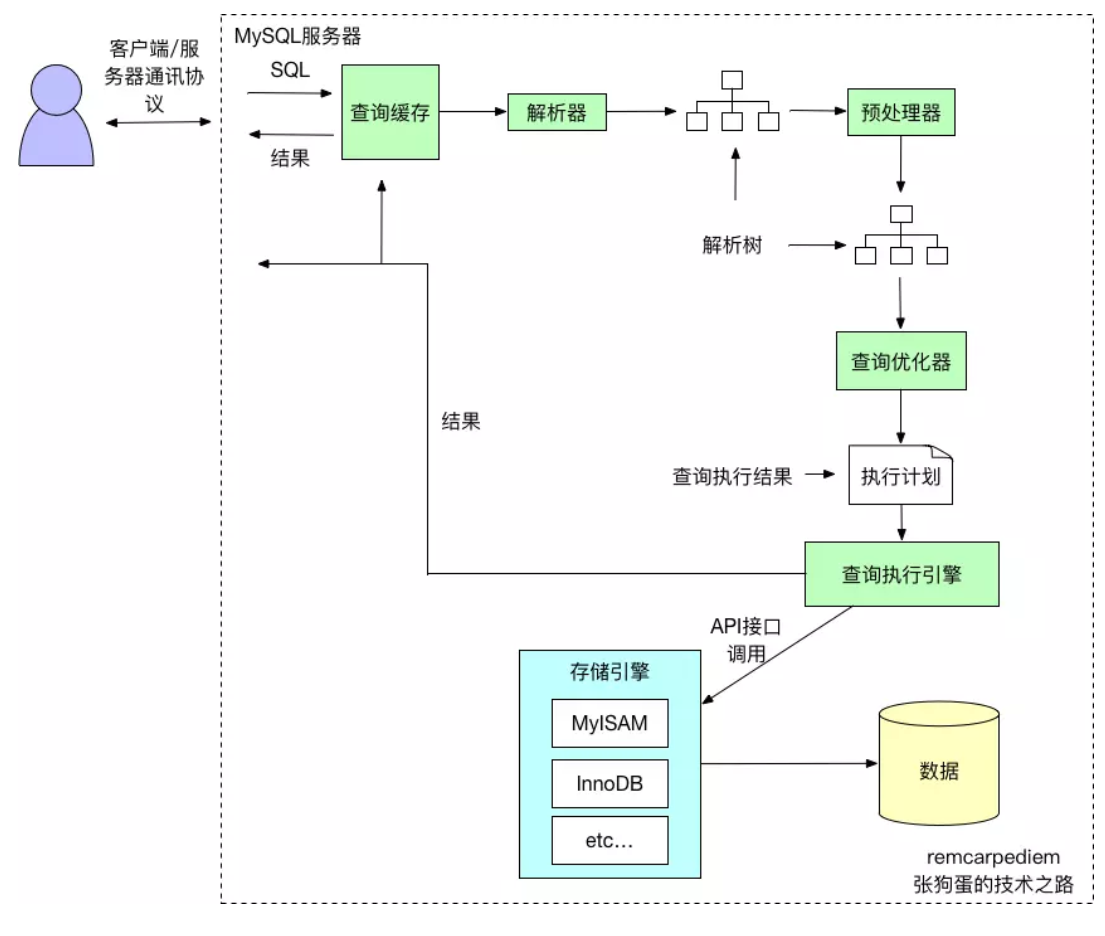
查询缓存
对查询缓存的优化是数据库性能优化的重要一环。判断流程大致如下图所示。  缓存命中率可以通过如下公式计算:Qcache_hits/(Qcache_hits + Com_select)来计算。
缓存命中率可以通过如下公式计算:Qcache_hits/(Qcache_hits + Com_select)来计算。
解析和预处理
查询优化器
查询优化器会将解析树转化成执行计划。一条查询可以有多种执行方法,最后都是返回相同结果。优化器的作用就是找到这其中最好的执行计划。 生成执行计划的过程会消耗较多的时间,特别是存在许多可选的执行计划时。如果在一条SQL语句执行的过程中将该语句对应的最终执行计划进行缓存,当相似的语句再次被输入服务器时,就可以直接使用已缓存的执行计划,从而跳过SQL语句生成执行计划的整个过程,进而可以提高语句的执行速度。  MySQL使用基于成本的查询优化器(Cost-Based Optimizer,CBO)。它会尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最少的一个。 优化器会根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会生成另外一个关系表达式,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,然后CBO会根据统计信息和代价模型(Cost Model)计算每个执行计划的Cost,从中挑选Cost最小的执行计划。由上可知,CBO中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响CBO选择最优计划。 有关优化器的原理十分复杂,这里就不进行详细讲解了,大家可以自行学习。
MySQL使用基于成本的查询优化器(Cost-Based Optimizer,CBO)。它会尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最少的一个。 优化器会根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会生成另外一个关系表达式,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,然后CBO会根据统计信息和代价模型(Cost Model)计算每个执行计划的Cost,从中挑选Cost最小的执行计划。由上可知,CBO中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响CBO选择最优计划。 有关优化器的原理十分复杂,这里就不进行详细讲解了,大家可以自行学习。
查询执行引擎
返回结果给客户端
总结
最后更新于